论文地址:Asynchronous Methods for Deep Reinforcement Learning ICML 2016
引子 & 总结
这篇文章的Motivation比较简单,据论文所说,是为了在Experience Replay之外,找到一种训练深度强化学习网络的方法。
文章中提出了多种算法,但是最出名的是A3C算法,在更短时间内,达到甚至超过了 Experience Replay 的 Performance。A3C的思路极其简单,可以在此之上做很多A+B之类的研究。
A3C的想法是这样的:每个agent在自己独立的环境中进行探索,互不干扰。每个agent都在执行自己的Actor-Critic 算法,进行一定次数的探索之后,得到policy network 和 value-network的梯度,异步更新全局的 policy network 和 value-network。
A3C与Experience Replay都在试图解决同一个问题:
用强化学习的方法训练Network的一个难点在于 强化学习获得的样本是连续的,这种连续性会干扰神经网络的学习,降低网络的收敛速度和性能。为了解决这个问题,Experience Replay通过随机采样memory中的transition,使得同一batch中各个transition之间在时间顺序上互不相干,从而解决了这个问题;但是Experience Replay的性质,导致它不能用于on-policy RL算法。
A3C某种程度上也是在做同样的事情
This parallelism also decorrelates the agents’ data into a more stationary process, since at any given time-step the parallel agents will be experiencing a variety of different states.
但是,与Experience Replay不同的是,它可以用于on-policy RL算法。
Motivation
Experience Replay存在缺点:
- 需要大量计算资源(GPU,memory)
- 仅适用于 off-policy 算法
有没有其他方法?
算法
这篇论文的基本想法在引子中提到了,这里不再重复。这种思想可以与很多RL算法结合,比如 Q-learning:

还可以和 Actor-Critic结合,得到著名的A3C:

这个算法和 Actor-Critic没区别,只是多了并行异步的部分。
n-step bootstrapping:每个线程中对于value network和 policy network的更新都是 n-step bootstrapping的。与 Sutton Book中给出的n-step bootstrapping算法基本相同,只是有一点区别:
在A3C中,每隔 $t_{max}$ 步骤停下来进行更新,从 $t-1 $ 更新到 $t_{start}$。对于 $t-1$ , $G_{t-1} = R_{t} + V(s_t)$( $G_t$ 即上图中的 $R$),对于 $t - 2$ , $G_{t-2} = R_{t-1} + R_{t} + V(s_t)$ ….。可以这么不严谨的理解,对于 $t-1$,相当于 TD(0),对于 $t-2$ 相当于 TD(1),对于 t_start,相当于 TD(t_max - 1),是bootstrapping from last state。
正则项:为了鼓励exploration,在Loss Function末尾加上 $H\left(\pi\left(s_{t}\right)\right)$ ,这里 $H$ 代表entropy 。
可以这么理解entropy和鼓励exploration之间的关系:当 $\pi$ 给出的概率分比较分散的时候,entropy比较大,即 $H\left(\pi\left(s_{t} ; \theta^{\prime}\right)\right)$ 比较大。加上这一 ”正则项“ 使得 $\pi$ 给出的概率不集中于某一个action,而是比较分散,即鼓励exploration。、
网络结构:feature extractor (CNN) 共享,最后有两个独立的输出层——1)policy network的fc + softmax层;2)value network的 fc 层。
Experiments
Atari 2600: 与Experience Replay的对比
与Experience Replay的对比分两部分。
1. 收敛速度
A3C(在16 个CPU核上)比 DQN(K40)收敛更快。
鉴于这篇文章想要challenge的是DQN中的Experience Replay,所以做了大量与DQN相关的对比实验。论文选取了5个Atari 2600中的游戏,比较DQN与这篇论文提出的算法的性能。明显看到,A3C的收敛速度要快很多:
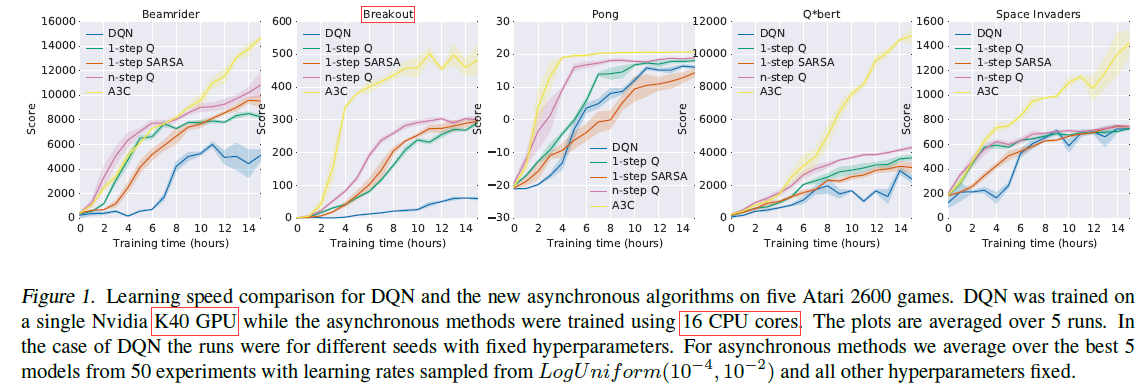
注:出于公平,A3C没有选DQN表现最差的游戏(可能A3C在这些游戏上表现也不好),比如 Breakout(打砖块)在DQN下面的结果也很好(不过不是最好的)。
注:论文里没有比较A3C和 Prioritized DQN or Dueling D-DQN的收敛速度
2. Scores
不仅收敛速度 A3C更快,充分训练后的performance也是最好的:
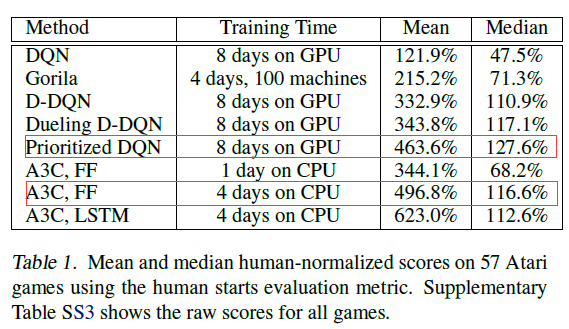
注:公平的对比是红框之间的对比,因为DQN没有用到LSTM,红框之间的网络结构是相同的。而A3C,LSTM 用到了LSTM。
更多实验:TORCS, MoJoCo, Labyrinth
论文中还做了一些其他实验,但是没有涉及和Experience Replay的比较,这里就略了。
Scalability
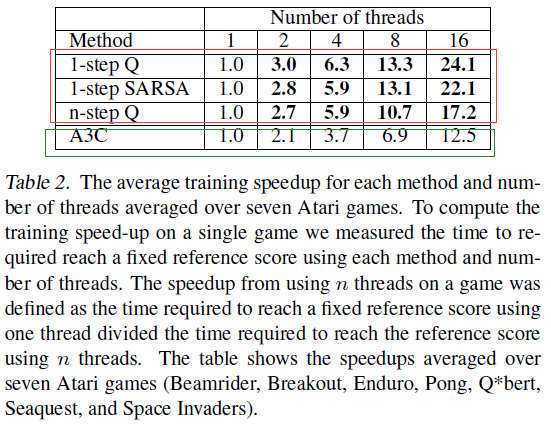
这部分展现的是 线程个数对收敛速度的影响。
对于前三种方法而言,令人惊讶的是 加速比竟然大于了 线程数量(这在普通多线程中是不可能的的),这说明多个线程同时更新一个模型可以加速模型的训练。
We believe this is due to positive effect of multiple threads to reduce the bias in one-step methods.
然后对于最有效的 A3C 来说,似乎没有这种效果(论文中似乎没有解释原因),但是加速比也很好了。
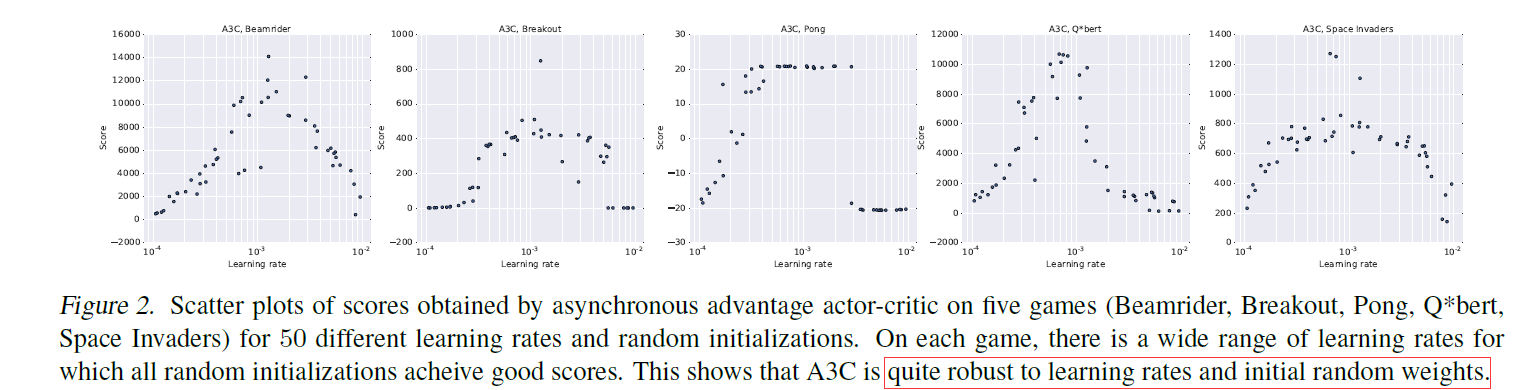
Robustness
这里展现的是A3C对与learning rate和网络初始化方式不敏感,不需要特别细致的调参。
Conclusion
这篇文章提出了一种比较泛用的算法框架,可以非常方便的与online RL算法做结合,并取得不错的效果。
这篇文章提出的方法具有以下优点:
- 考虑到 Experience Replay需要大量的内存存放transition以及GPU,这篇文章的方法运作在CPU上,需要的资源更少,但也具有加速/稳定深度强化学习算法的作用。
- 此外,A3C的算法与Replay并没有冲突,所以二者可以结合,达到更好的效果,尤其是某些环境的transiton来之不易,需要多次复用(比如论文中的TORCS)。
- 这篇文章提出的算法非常的general,所以有很多future work可以做,比如backward view n-step bootstrapping;与double Q-learning的结合等等
![[Paper][RL][ICLR 2016] Prioritized Experience Replay](/medias/featureimages/21.jpg)
![[Paper][RL][Nature 2015] DQN论文笔记 及 实现](/medias/featureimages/5.jpg)