论文:Human-level control through deep reinforcement learning
引子
这篇论文(DQN)将深度学习引入端到端的强化学习。为了提高stability和加快网络收敛,论文又提出了Experience Replay 和 target network。DQN在Atari 2600的大部分游戏上,达到了跟人类差不多的游戏水平。
对于Atari 2600的40多种游戏,DQN都使用了同一个网络结构,同一套超参,得到了不错的结果,这意味着DQN具有普适性,不是只针对某个问题的特殊解。
来源:Sutton Book 2nd Edition
Creating artificial agents that excel over a diverse collection of challenging tasks has been an enduring goal of artificial intelligence. The promise of machine learning as a means for achieving this has been frustrated by the need to craft problem-specific representations. DeepMind’s DQN stands as a major step forward by demonstrating that a single agent can learn problem-specific features enabling it to acquire humancompetitive skills over a range of tasks. This demonstration did not produce one agent that simultaneously excelled at all the tasks (because learning occurred separately for each task), but it showed that deep learning can reduce, and possibly eliminate, the need for problem-specific design and tuning.
总结
Features的提取: 当task中的状态数目超过一定数量时,必须采用Function Approximation(FA)的方法,这意味着需要将 $state$ 转换为 $feature$,这是一个non-trivial的问题。有没有一个end2end普适性特征提取方法吗?
这篇文章是在2015年发表的,那几年,许多人都尝试将神经网络引入他们的领域,比如 RCNN。CNN非常善于从图像中提取特征,和DQN的setting完美吻合。但是,将CNN和FA结合起来,做端到端的训练并不容易,神经网络会引入很多问题。
CNN的训练:CNN的训练是mini-batch方式的,而强化学习的场景一般是online的(边探索边学习)。如何将online转化为batch learning 呢?最naive的想法:在agent探索的时候,每隔32个step,收集32个$(state, action) \rightarrow Q$ 作为一个batch训练网络,然而这种时间上强关联的样本,会误导神经网络,让CNN的训练十分困难。
DQN为了解决这个问题,引入了1) Experience replay 打散同一个batch种相邻样本的相关性。
其次,为了解决Q-learning中的semi-gradient,提出了2)Target Network。
在附录的Ablation Study中,DQN作者展示了1)和 2)的重要性:(图中为每个episode的平均得分,越大越好)
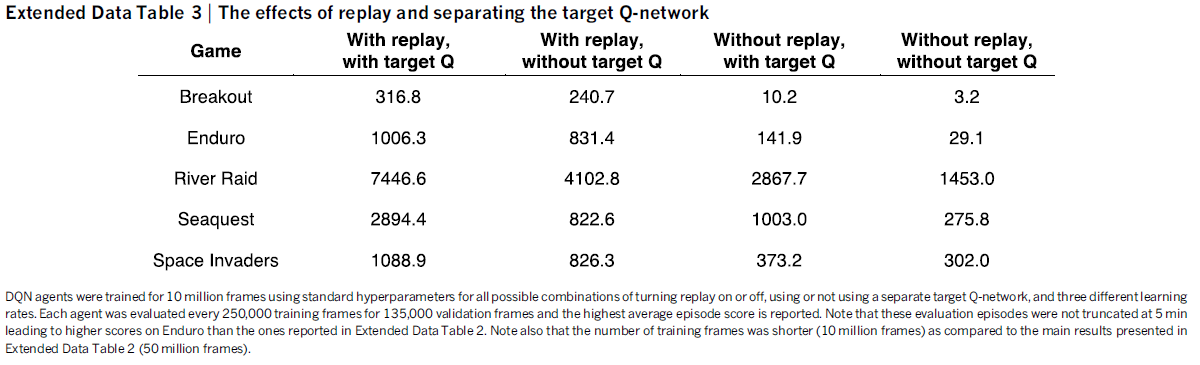
(注:关于Target Network的作用,DDPG论文中也有做对比实验,感兴趣可以结合着看)
- 实验场景:Atari 2600对人来说具有一定的游戏难度,人的分数不会太高(所以论文做到了Human Level,发在了Nature上);图像大小比较小,不需要太深的网络就可处理,训练难度较低。
算法
网络结构
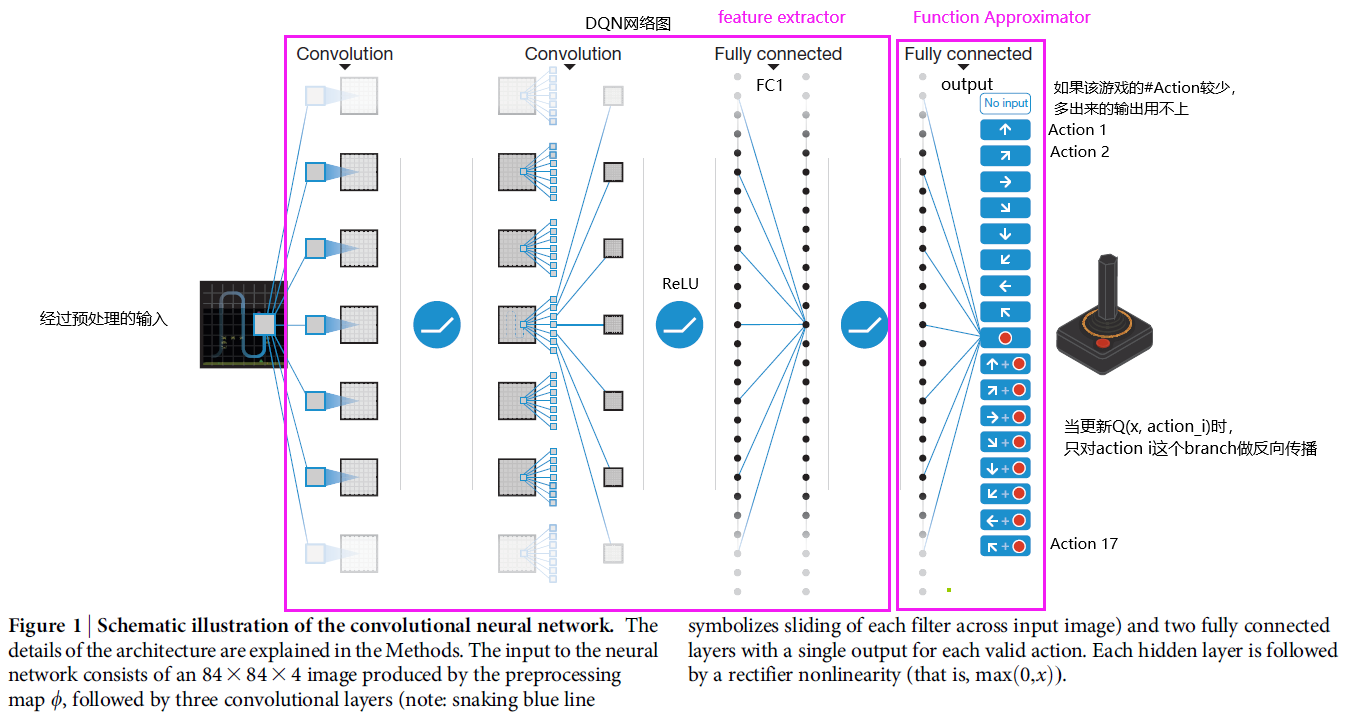
算法重点
1. Experience Replay
概念:在传统的Q-learning中,智能体(agent)在 $s_t$ 中执行 $a_t$ ,得到Reward $r_t$,和下一个状态 $s_{t+1}$。此时根据 Q-learning的更新公式有:
将 $e_t = (s_t, a_t, r_t, s_{t+1})$ 带入上式更新 $\theta$($e_t$ 为t时刻的transition或experience)。
然而在 Experience Replay 中,智能体在 $s_t$ 中执行 $a_t$ ,得到Reward $r_t$,和下一个状态 $s_{t+1}$。却并不是直接将 $ e_t = (s_t, a_t, r_t, s_{t+1})$ 带入上式,而是将 $e_t$ 放入一个固定大小的experience pool $D$ 中;然后,从 $D$ 中 均匀随机采样出 $B$ 个 $e$ 作为一个batch,比如$\{e_{1984}, e_{38711}, e_{230},…. \}$ ,代入上式。
淘汰:既然 $D$ 是固定大小的,那当 $D$ 满了之后,需要淘汰最早进入 $D$ 的transition。
优势:Experience Replay的优势论文中提到三点:
- 重复使用 Transition,提高data effienciy。传统的Q-learning中,transition使用一次便丢弃了。
- 打散连续transition之间的相关性,同一个batch中的transition都是时间上不相邻的。如果同一个batch之间是相邻的,会影响网络的训练。
off-policy:Experience Replay 只能用在在off-policy算法上上。on-policy中,当我们利用transition $e_t$更新policy时,$e_t$是同一个policy所生成的。然而在Experience Replay的更新中,每次用很久之前的某个transition $e_j$更新 $Q$, 而生成 $e_j$ 的 policy早已不是当前的policy了,在从 $j \rightarrow t$的这段时间中,policy已经改变了 $t-j$ 次了(因为policy本质上就是 $Q$ ,而 $Q$ 一直都在变)。自然而然,这篇paper选用了一个off policy的算法,Q-learning。
2. Target Network
在 Sutton 的书中,提到了 semi-gradient Q-learning。下式为Q-learning的Loss Function:
如果类比监督学习,那么groundtruth $y_t = r_t + \gamma * max_{a}Q(s_{t+1}, a;\theta)$,但是与监督学习不一样,$y$ 中还涉及了 $\theta$ 。论文中提出的解决方式是用一个target Network(参数为 $\theta^{-}$)替换 $y$ 中的网络 (参数为 $\theta^{}$),这样一来,loss function变为了如下形式:
现在 $y_t$ 与 $\theta$ 没有关系了,可以按照监督学习的那一套更新 $\theta$。
(每隔 $C = 10000$ 个 timestep,更新 target Network中的值:$\theta = \theta^{-}$)
(注:DDPG中对target network进行了一个小的改动(soft target network))
其他细节
1. 预处理
在t时刻,得到210x160x3的RGB图像 $x_t$,然后进行如下转换:1)变为灰度图像 210x160x1 2)resize为 84x84的图像 3)与 $x_{t-1} x_{t-2}, x_{t-3}$ 的图像stack到一起,得到 84x84x4 ndarray,称之为 $\phi(x_t)$。 $\phi(x_t)$ 就是每一步的状态 $s_t$
2. Error Clamp
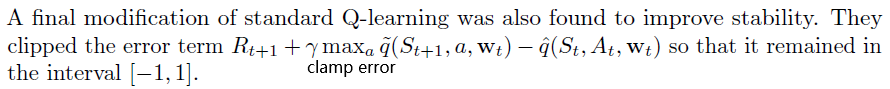
完整的算法

Experiments
具体的数据这里就不放了,感兴趣的可以去看论文,这里重点说一下DQN的可视化以及不足之处。
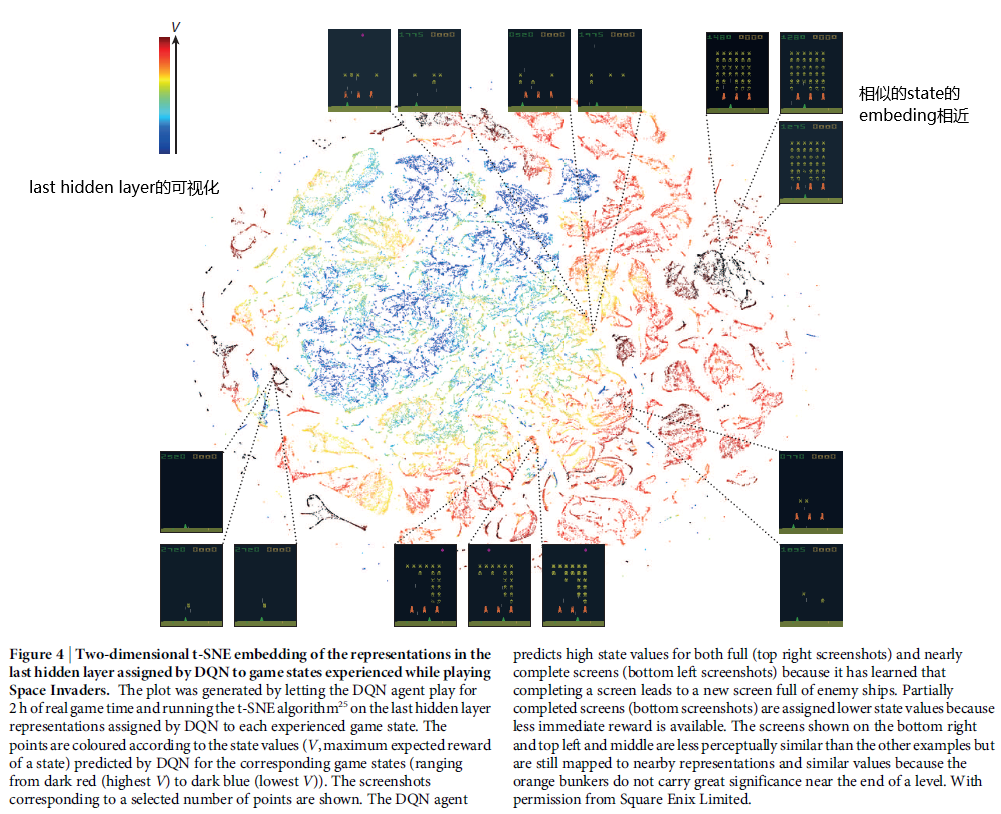
embedding可视化
作者用t-SNE可视化了embedding(last hidden layer的输出)。在CNN分类中,一般相同类别的图像的embedding相近,在DQN中也是如此,这可以佐证DQN的网络是有意义的,提取到了不错的特征:
DQN的不足
Sparse Rewards 总的来说,DQN在大部分游戏上表现得还不错,但是在某些游戏上得表现并不比random player要好,比如Montezuma’s Revenge。跟breakout不同,这是个相当难的游戏,任何小的失误都会导致死亡,这意味着agent刚开始学习时很难获得reward。在漫长的学习过程中,agent获得的奖励是相当稀疏的(sparse rewards)[2]。
Sparse rewards问题是Deep RL 难以解决的问题。不过,后续有一些工作利用human demonstrations,不再让agent自己探索环境,而是让网络模仿人类学习[3] [4]。
大量内存: Replay Memory需要大量空间资源
off-policy: 由于Experience Replay用的是old-policy的sample更新当前的policy,所以原则上 Experience Replay只能使用off-policy算法。
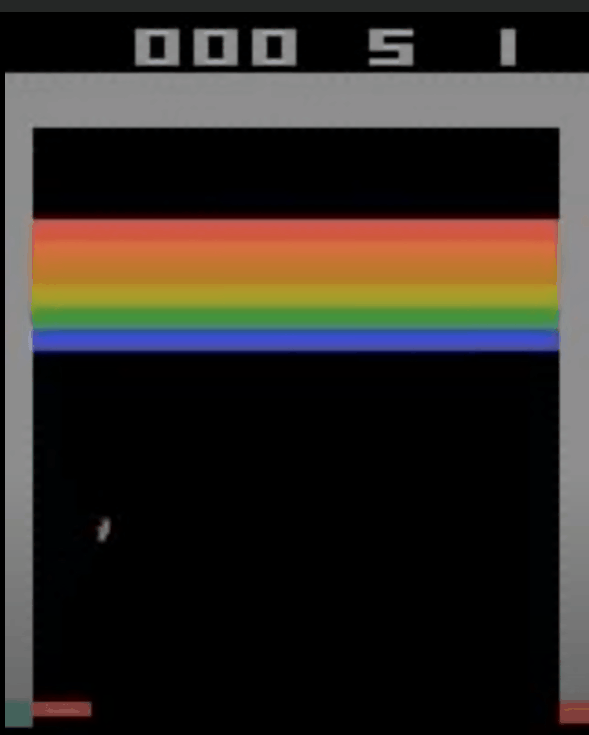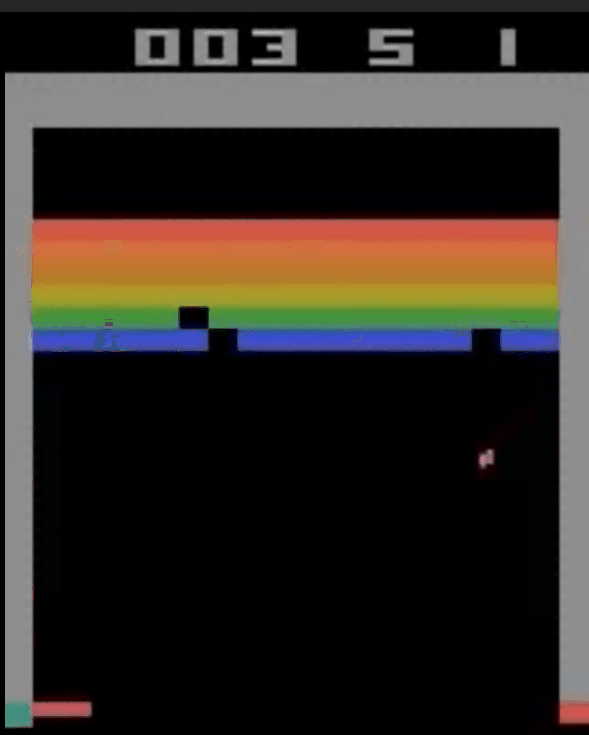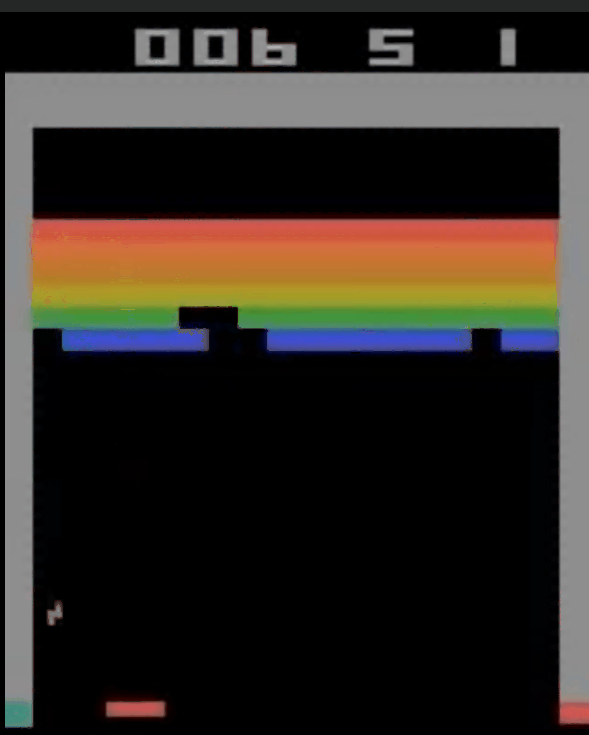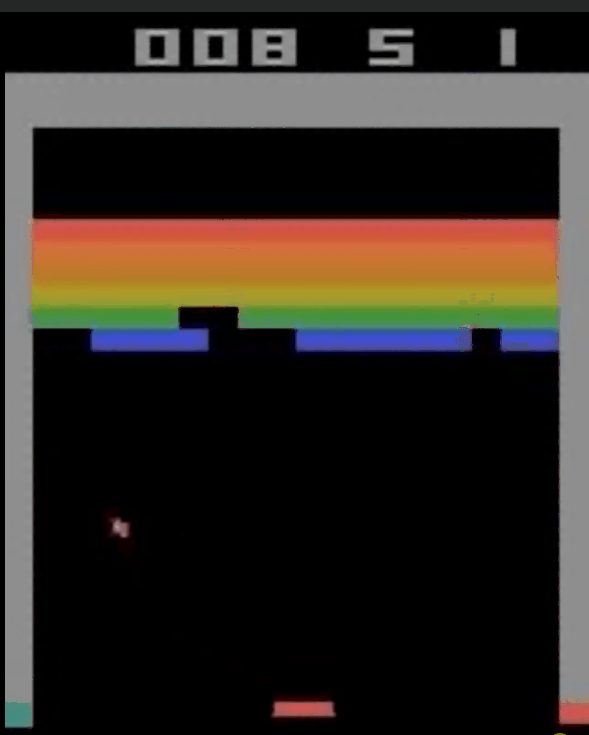
复现 & 结果
代码在我的github:https://github.com/LamForest/RL-learning/blob/master/DQN/Deep%20Q%20Learning.ipynb
刚开始训练的网络:
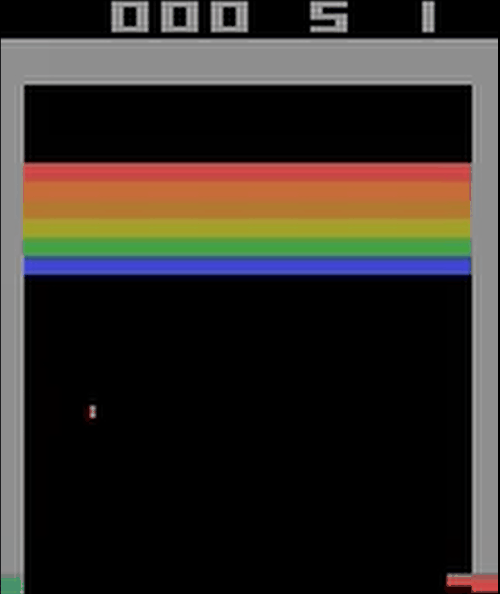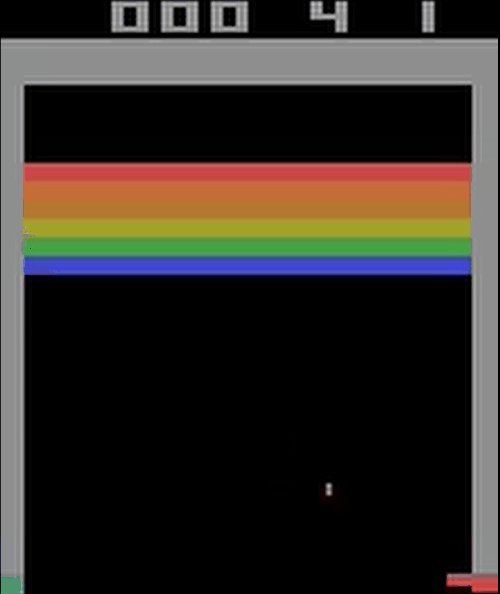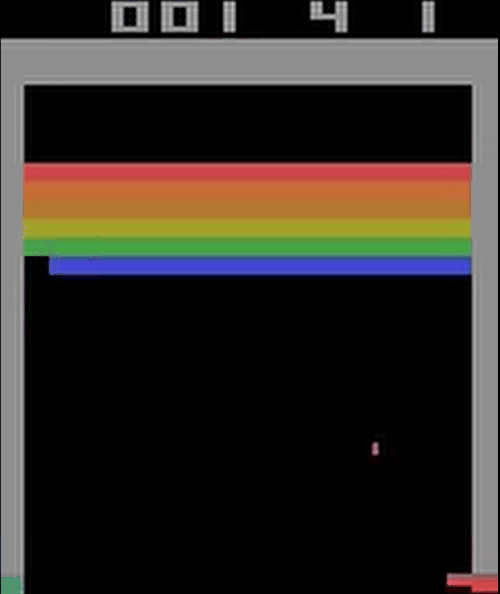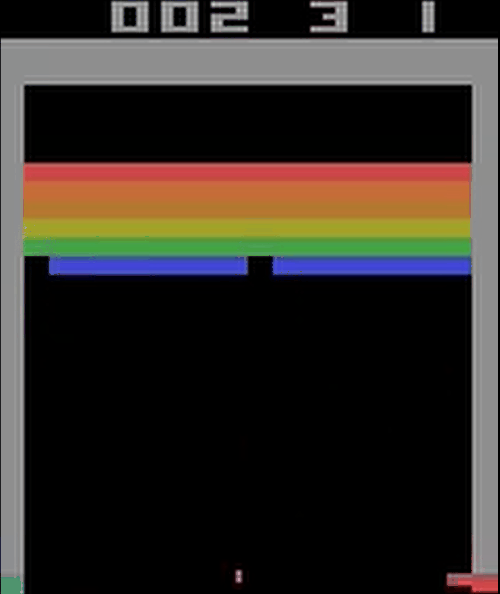
训练6000个episode后的网络
参考资料
[1] https://stats.stackexchange.com/a/265001
[2] https://awjuliani.medium.com/on-solving-montezumas-revenge-2146d83f0bc3
[3] Playing hard exploration games by watching YouTube https://arxiv.org/pdf/1805.11592.pdf
[4] Observe and Look Further: Achieving Consistent Performance on Atari https://arxiv.org/pdf/1805.11593.pdf
![[Paper][RL][ICML 2016] A3C](/medias/featureimages/3.jpg)
![[强化学习][python] 在 tic-tac-toe 上实现 蒙特卡洛搜索树 MCTS 算法](/medias/featureimages/4.jpg)