论文:[AAAI 2018] Rainbow: Combining Improvements in Deep Reinforcement Learning
引子
顾名思义,Rainbow是各种颜色的集合,也是各种 Deep Q-learning RL算法的合体。这篇文章做了以下事情:
- 将6种Deep Q-learning RL算法组合成Rainbow算法
- 做了大量实验,研究了各种算法对Rainbow的影响,并稍微解释了造成影响的原因。
总的来说,这是一篇实验导向型的文章,对于实验结果的解释和讨论不够充分。今年 ICML 有一篇论文 后续工作: [ICML 2021]Revisiting Rainbow: Promoting more Insightful and Inclusive Deep Reinforcement Learning Research 对Rainbow的结果进行了更深入的分析和解释,不过在某些方面,得出了和Rainbow不一样的结论,有兴趣的可以看看。
Related Work
DQN
Priortized Experience Replay
Double DQN
- Dueling Network
- A3C (A3C是Actor Critic算法,这篇论文只是利用它的multistep思想)
Distributional RL (Distributional不是指分布式RL,而是指学习目标从 expected retrun 变为 value distribution)
Noisy Nets
算法
尽管 以上 6 种算法各不相同(DQN属于公有部分),但是它们从不同的角度在改进DQN,彼此之间并不冲突,将它们综合在一起并没有想象中那么困难。
从Distributional RL 开始,Distributional RL学习的目标为 #atom = N 的离散概率分布,直接将Distributional RL 的 cross entropy 的loss function拿来就好了,不需要额外的改动。
Multistep reward: 这个其实也就是将Distributional RL的target distribution做一个小的修改。Distributional RL是在一步 $\hat{\mathcal{T}} z_{j} = R + \gamma Q(s_{t+1},a)$ 后进行projection,得到target distribution $\Phi_{\boldsymbol{z}} d_{t}^{(1)}$。Rainbow是在多步 $\hat{\mathcal{T}}^{(n)} z_{j} = R_{t+1} + … + R_{t+n} + \gamma^n Q(s_{t+n},a)$ 之后进行投影,得到target distribution $\Phi_{\boldsymbol{z}} d_{t}^{(n)}$。 loss function为:
Double DQN:在 $\hat{\mathcal{T}}^{(n)} z_{j} = R_{t+1} + … + R_{t+n} + \gamma^n Q(s_{t+n},a)$ 中,$Q$ 由 target network计算,$a$ 的选择由online network计算,与 Double DQN一致,即:
Priortized Experience Replay中样本被选中的概率正比于TD error $\delta = R + \gamma$ 。在Distributional RL 的框架下, 样本被选中的概率正比于TD error $D_{KL}$。 因为,TD error和 $D_{\mathrm{KL}}$ 是等价的概念。
Dueling Network: 在 Distributional RL 的框架下, Dueling Network也只需要做一点小的改动。仍然是有个共享卷积 $\xi$, value branch $\eta$ 的输出维度从 1 变为 #atoms,而 advange branch $\psi$ 的输出维度从 #actions 变为 #actions x #atoms。输出层的构造方式仍然和 Dueling Network 中的一样。
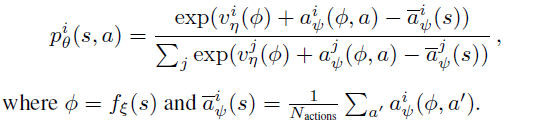
- Noisy Net:没有变化,仍然是用Noisy layer代替神经网络中的 $\boldsymbol{y}=\boldsymbol{b}+\mathbf{W} \boldsymbol{x}$ layer:
至此, 6种 DQN的improvement 集于一身,得到了 Rainbow。
实验
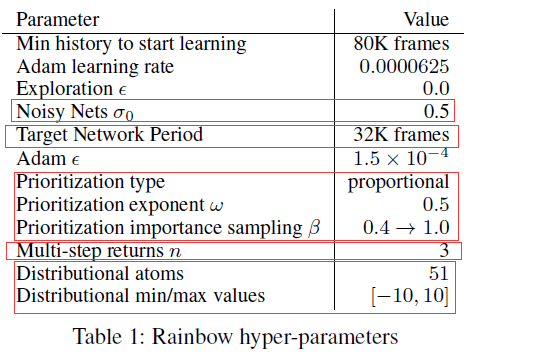
超参tuning
不同论文都会引入不同的超参,可以想象,Rainbow 的作者花了很多时间调参,也在论文中分享了一些经验,感兴趣的可以去看论文,这里展示作者的调参结果:
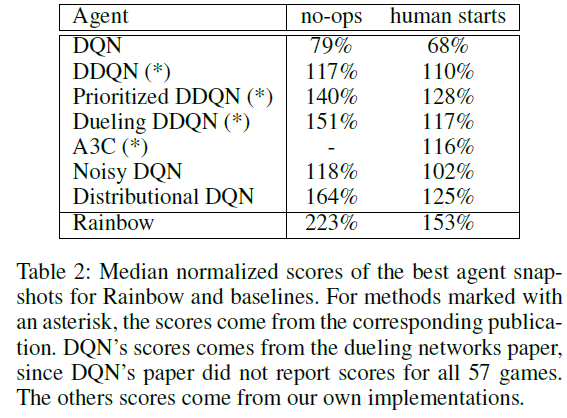
Results on Atari
Ablation study
显而易见,将各种方法结合起来肯定会提高scores。但是,我们更感兴趣的是,哪种方法的提升更大?作者做了相关的Ablatioin Study,将每个方法分别从Rainbow中移除,观察移除后的scroes。
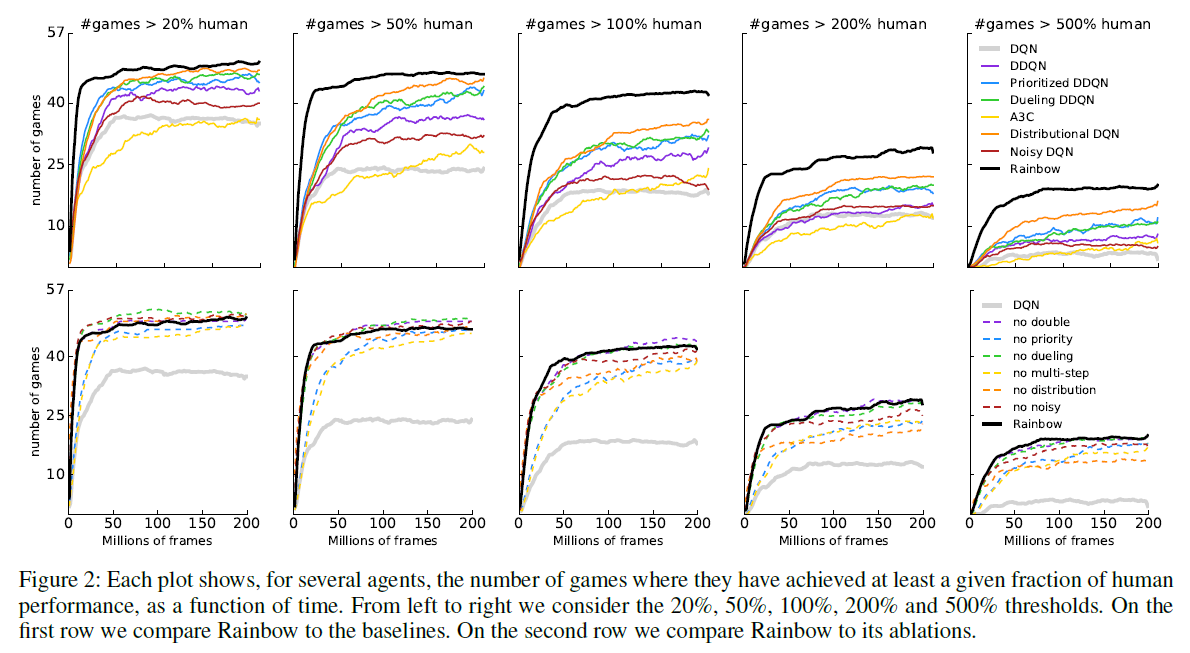
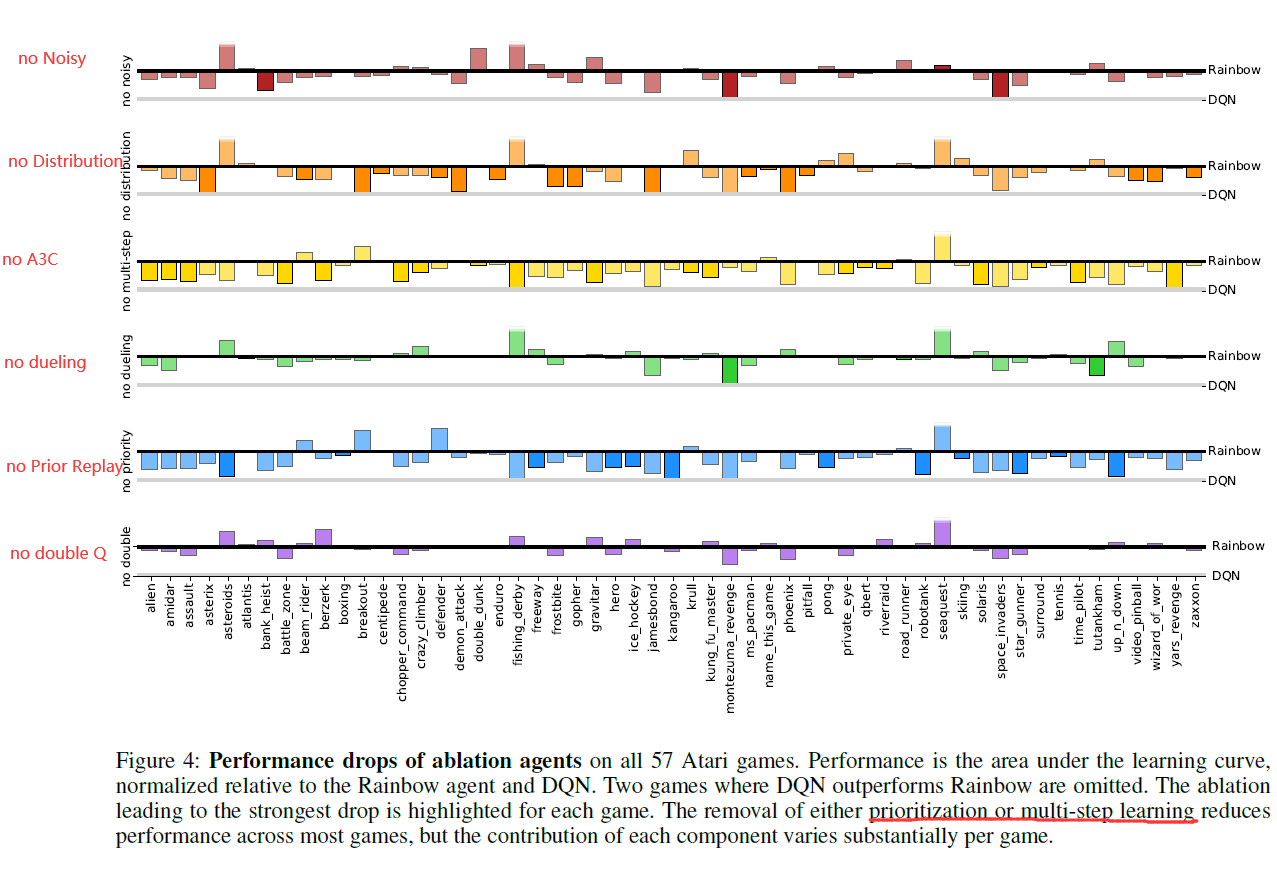
从图上可以看出几点(更详细请看论文):
- Prioritized replay,multi-step learning 的移除对结果影响最大。
- 其次是 Disbritional DQN,再其次是 Noisy Net。
- 对于 Dueling network,在 >20% >50% human上,移除dueling甚至会提升结果。作者没有解释原因。
- 移除Double Q-learning同样会提升结果,作者认为,这是因为true Q值一般在10以上,而Distributional DQN将Q clip到了 -10 10之间,相当于产生了underestimation,这与 Double Q-learning的设计目的(解决overestimation)产生了冲突。所以,加上了Double Q-learning甚至产生了副作用。
![[Paper][RL][Nature 2016] AlphaGo: Deep RL 与 Tree Search 的成功结合](/medias/featureimages/6.jpg)
![[Paper][RL][ICML 2017] Distributional RL](/medias/featureimages/4.jpg)