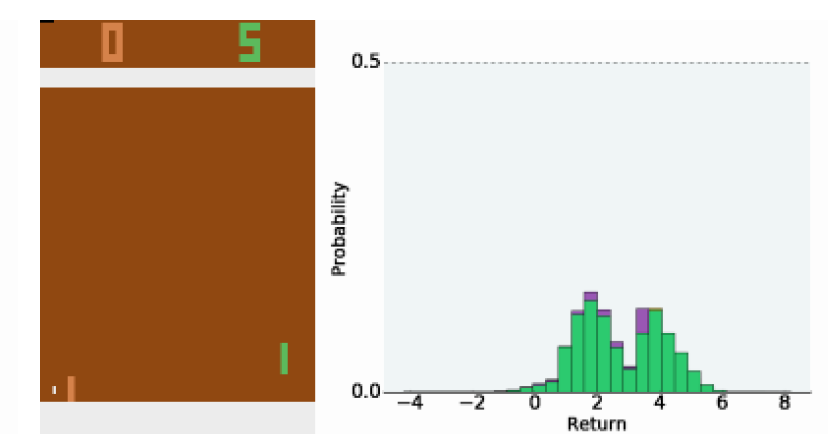
论文:ICML 2017 A Distributional Perspective on Reinforcement Learning
引子 & Motivation
Motivation & idea: Approximate value distribution instead of expected return.
然而,idea虽然简单,实现起来却并不容易。最简单的想法使用一个 高斯分布 对 $Q$ 建模,然而这其实与 approximate expected return区别不大。这篇文章采取的是另一种方法,这使得所拟合的分布不仅限于 单峰形态的概率分布函数(比如 高斯分布):
理论
略
算法
1. 区间离散化
如何方便的建模任意的概率分布函数呢?作者使用了一个离散分布来建模:
将 $[V_{min}, V_{max}]$ 上均匀采样 $N$ 个点,$z_0, z_1, …z_{N}$。($V_{min}, V_{max}, N$ 是三个超参,在本文的实验部分,使用的超参为 $-10, 10, 51$,即相邻点的相差 $0.4$。
每个点的概率 为
这里的 $\theta_{i}(x, a)$ 为需要学习的神经网络,神经网络的输出通过归一化转化为概率。
2. Projected Bellman Update
DQN中的target value 为 :
这篇论文中的target distribution为:
计算 next state 的 best action $a^*$ 的distribution:
计算 离散点 $z_j$ 经过Bellman Update后所处的位置:
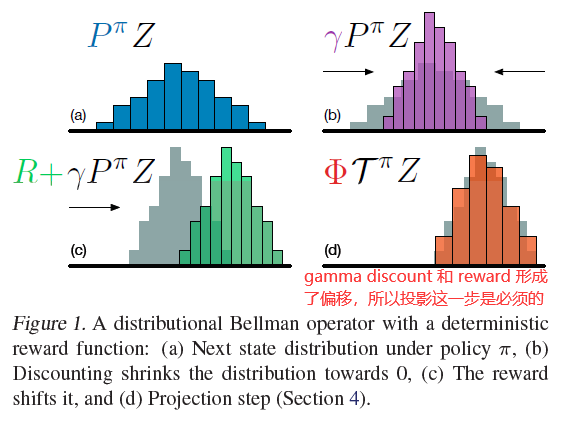
- 由于 $\gamma$ 和 $r_t$ 影响,Bellman Update之后的 $\hat{\mathcal{T}} z_{j}$ 可能并不在预先设好的离散点 $z_0, z_1, …z_{N}$ 上。于是根据 $\hat{\mathcal{T}} z_{j}$ 与相邻离散点 $l,u$ 的 距离将 $p_{j}\left(x_{t+1}, a^{*}\right)$ 分配到 $l,u$ 上。( $l,u$ 是 $z_0, z_1, …z_{N}$ 中的点):
- 所得到的 $m_0, m_1, ….m_N$ 即为 target distribution 的 每个离散点 $z_0, z_1, …z_{N}$ 上的概率。这里由于是两个概率之间的差值,所以loss function采用cross-entropy :
至此,得到最终的算法:

附示意图一张:
Experiments
待补充
Discussion
待补充
![[Paper][RL][AAAI 2018] Rainbow](/medias/featureimages/21.jpg)
![[Paper][RL][ICML 2016] Dueling DQN](/medias/featureimages/19.jpg)